7. GWAS Analysis
2 different software packages will be used to perform the GWAS analysis. Each one uses a different statistical approach to adjust for population stratification. The genomic control λ will be used to assess the efficiency of each.
7.1. GWAS by Plink
7.1.1. Logistic regression model
PLINK 2.0 has the new --glm command for association analysis (instead of --linear and --logistic in Plink 1.9). For quantitative phenotypes, --glm fits a linear model while for binary phenotypes, it fits a logistic or Firth regression model instead.
- The model has a fixed-covariate matrix to include covariates loaded by
--covar.- It is now standard practice to include top principal components (usually computed by
--pca) as covariates in any association analysis, to correct for population stratification. - The 'sex' modifier can be added to include ".fam/.psam" sex as a covariate. If this is not of interest, add the 'no-x-sex' modifier instead.
- It is now standard practice to include top principal components (usually computed by
- Dataset precautions:
- This method does not properly adjust for small-scale family structure. As a consequence, it is usually necessary to prune close relations.
- It is advised to exclude variants with very small minor allele count ("--mac 20" is a reasonable filter to apply).
The current filtered dataset already fulfill these precautions.
- The model uses the minor allele dosages by default. To make it always contain ALT allele dosages instead (the A1 column of the main report), the 'omit-ref' modifier needs to be added.
- Covariates are typically used to adjust for their effect but their effect is not needed in the output file. The 'hide-covar' modifier can greatly reduce file sizes.
- --ci causes confidence intervals with the given width to be reported for each beta or odds-ratio.
Here, the data will be adjusted for sex and 3 PCs.
plink2 --bfile "$gwas"/AxiomGT1v2.filtered.${target}.noRelatives.LD_prune --chr-set 38 no-xy --allow-extra-chr \
--pheno $gwas/${target}.pheno \
--chr 1-38, X \
--glm sex 'hide-covar' --ci 0.95 \
--covar "$gwas"/AxiomGT1v2.filtered.${target}.noRelatives.LD_prune.pca.eigenvec --covar-name PC1,PC2,PC3 \
--output-chr 26 --out "$gwas"/AxiomGT1v2.filtered.${target}.noRelatives.LD_prune.glm
Here is the output:
...
Options in effect:
--allow-extra-chr
--bfile gwas_atopy/AxiomGT1v2.filtered.atopy.noRelatives.LD_prune
--chr 1-38, X
--chr-set 38 no-xy
--ci 0.95
--covar gwas_atopy/AxiomGT1v2.filtered.atopy.noRelatives.LD_prune.pca.eigenvec
--covar-name PC1,PC2,PC3
--glm sex hide-covar
--out gwas_atopy/AxiomGT1v2.filtered.atopy.noRelatives.LD_prune.glm
--output-chr 26
--pheno gwas_atopy/atopy.pheno
....
1989 samples (980 females, 1009 males; 1989 founders) loaded from
gwas_atopy/AxiomGT1v2.filtered.atopy.noRelatives.LD_prune.fam.
180605 out of 180689 variants loaded from
gwas_atopy/AxiomGT1v2.filtered.atopy.noRelatives.LD_prune.bim.
1 binary phenotype loaded (317 cases, 1672 controls).
3 covariates loaded from gwas_atopy/AxiomGT1v2.filtered.atopy.noRelatives.LD_prune.pca.eigenvec.
Calculating allele frequencies... done.
--glm logistic regression on phenotype 'PHENO1': done.
Results written to gwas_atopy/AxiomGT1v2.filtered.atopy.noRelatives.LD_prune.glm.PHENO1.glm.logistic .
7.1.2. Genomic control
The genomic control λ value (often referred to as the "genomic inflation factor") is used to measure and correct for population stratification. A λ value close to 1 suggests that the results are not inflated due to population stratification, while values greater than 1 suggest potential inflation. However, values up to 1.10 are generally considered acceptable for a GWAS.
The results of the regression analysis can be used to calculate the genomic control λ value.
## λ = observed median chi-square statistic / 0.456
## Chi-square statistic = Z_stat<sup>2</sup>
tail -n+2 $gwas/AxiomGT1v2.filtered.${target}.noRelatives.LD_prune.glm.PHENO1.glm.logistic | awk '{print $13*$13}' | sort | awk '{count[NR] = $1;}\
END{
if(NR % 2){gif = count[(NR + 1) / 2];} else {gif = (count[(NR / 2)] + count[(NR / 2) + 1]) / 2.0;}
print "Genomic inflation factor = " gif/0.456;}'
Genomic inflation factor = 1.0748.
7.1.3. Plotting
input_asc="$gwas/AxiomGT1v2.filtered.${target}.noRelatives.LD_prune.glm.PHENO1.glm.logistic"
output_prefix="$gwas/${target}.glm.logistic"
Rscript -e 'args=(commandArgs(TRUE));require(qqman);'\
'asc <- read.table(args[1],head=TRUE,comment.char="");'\
'asc <- na.omit(asc);'\
'tiff(paste(args[2],".qqplot.tif",sep=""),units="in", width=10, height=10, res=300);'\
'qq(asc$P, main = "Q-Q plot", col = "blue4");'\
'dev.off();'\
'noOfTests <- dim(asc)[1];bonf <- 0.05/as.numeric(noOfTests);bonfBy200 <- 10/as.numeric(noOfTests);'\
'sigSNPs <- asc$ID[which(asc$P<=bonfBy200)];'\
'tiff(paste(args[2],".manh.tif",sep=""),units="in", width=30, height=10, res=300);'\
'manhattan(asc, main = "Manhattan Plot", chr = "X.CHROM", bp = "POS", p = "P", snp = "ID", ylim = c(0, 7), chrlabs = c(1:38, "X"),suggestiveline = -log10(bonfBy200), genomewideline = -log10(bonf), highlight = sigSNPs);'\
'dev.off();' "$input_asc" "$output_prefix"
Here is the Q-Q plot:
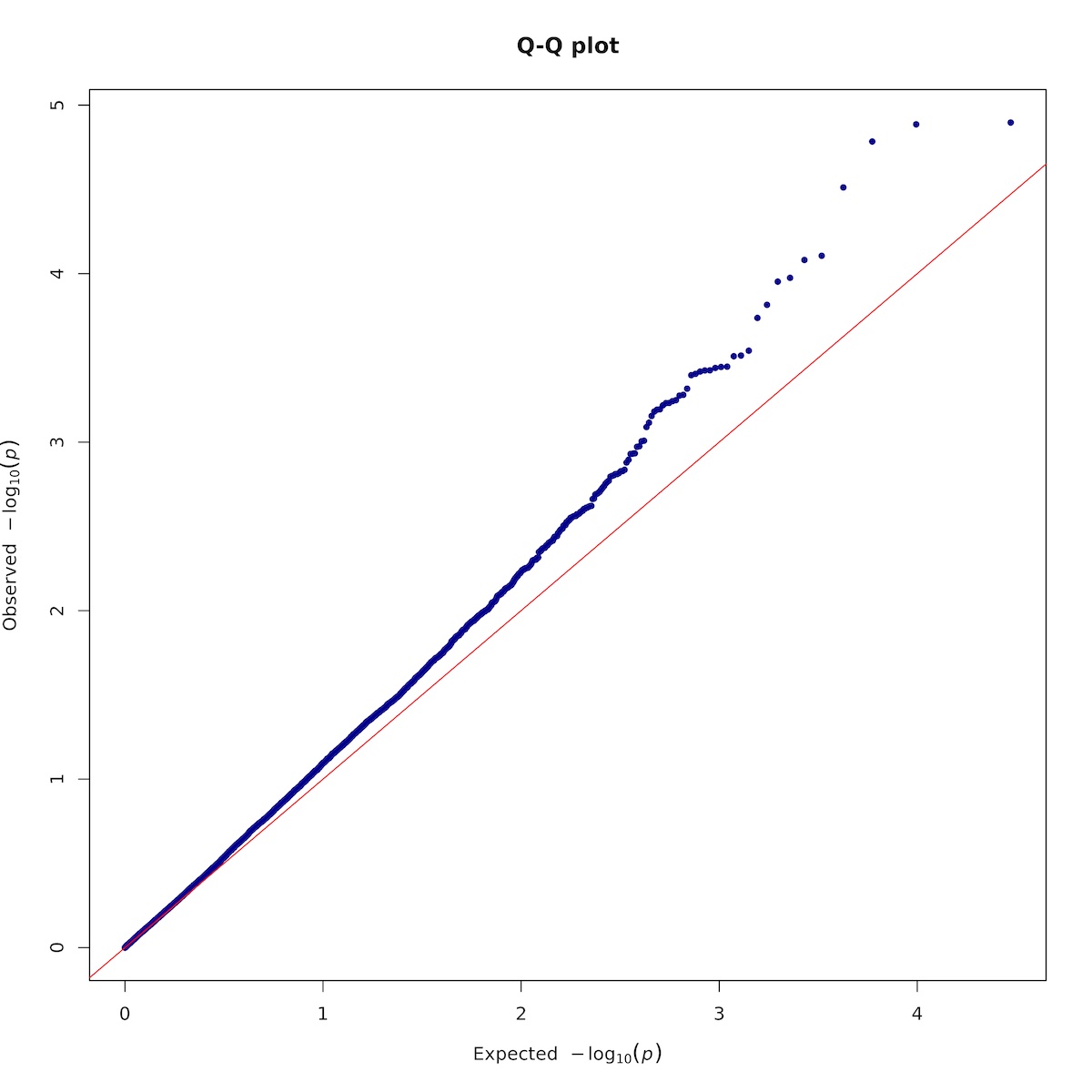
And the Manhattan plot:
7.2. GWAS by GCTA
7.2.1. Mixed linear model
Mixed model association software such as SAIGE, BOLT-LMM, GCTA or FaST-LMM instead; or regenie's whole genome regression can better handle genetic relatedness. In this tutorial, --mlma-loco for mixed linear model-based association analysis will be used.
where:
- y is the phenotype.
- a is the mean term (i.e. intercept).
- b is the additive effect (fixed effect) of the candidate SNP to be tested for association.
- x is the SNP genotype indicator variable coded as 0, 1 or 2.
- g is the polygenic effect (random effect) i.e. the accumulated effect of all SNPs (as captured by the GRM calculated using all SNPs).
- e is the residual.
The MLM leaving-one-chromosome-out (LOCO) analysis implements the model with the chromosome, on which the candidate SNP is located, excluded from calculating the GRM. This means that g is the accumulated effect of all SNPs except those on the chromosome where the candidate SNP is located. The var(g) will be re-estimated each time when a chromosome is excluded from calculating the GRM. The MLM-LOCO analysis is computationally less efficient but more powerful as compared with the classical MLM analysis.
Note1: The mixed linear model incorporates the genetic relationship matrix (GRM) to capture the accumulated effect of all SNPs which accounts for population stratification to a large extent. Therefore, there is no need to adjust for top PCs.
Note2: By default, the model includes covariates (if provided) as fixed effects and the phenotype will be adjusted by the mean (i.e. intercept) and covariates before testing for SNP association. However, if SNPs are correlated with the covariates, pre-adjusting the phenotype by the covariates will probably cause loss of power. If the
--mlma-no-preadj-covaroption is specified, the covariates will be fitted together with the SNP for association test. However, this will significantly reduce computational efficiency.
gcta64 --mlma-loco --bfile gcta_atopy/AxiomGT1v2.filtered.${target}.noRelatives.LD_prune.gcta --autosome-num 38 --autosome \
--grm gcta_atopy/AxiomGT1v2.filtered.${target}.noRelatives.LD_prune.gcta_grm \
--pheno $gwas/${target}.pheno \
--covar $gwas/gender.txt --mlma-no-preadj-covar \
--out $gwas/${target}_asc --thread-num 10
7.2.2. Genomic control:
The output of the MLM-LOCO analysis does not have chi-square statistic; however, the p-values can be converted to chi-squared statistics for 1 degree of freedom by using the inverse of the cumulative distribution function (CDF) of the chi-squared distribution. This can be easily done using Python.
## Prepare the conda environment to run Python.
mamba install -c conda-forge python=3.11.4 pandas=2.0.3 scipy=1.11.2
Now, Python can be opened in interactive mode by using the command python. Once analysis is done, interactive mode can be exited by using the exit() function.
import pandas as pd
import scipy.stats as stats
# Load the GCTA-LOCO results.
gwas_results = pd.read_table("gwas_atopy/atopy_asc.loco.mlma", delim_whitespace=True)
# Convert p-values to chi-squared statistics.
gwas_results['CHISQ'] = stats.chi2.ppf(1 - gwas_results['p'], df=1)
# Calculate lambda.
lambda_value = gwas_results["CHISQ"].median() / 0.456
print("Genomic control λ:", lambda_value)
Genomic control λ = 1.0349228106573256 which is GREAT!
7.2.3. Plotting
input_asc="$gwas/${target}_asc.loco.mlma"
output_prefix="$gwas/${target}.loco.mlma"
Rscript -e 'args=(commandArgs(TRUE));require(qqman);'\
'asc <- read.table(args[1],head=TRUE,comment.char="");'\
'asc <- na.omit(asc);'\
'tiff(paste(args[2],".qqplot.tif",sep=""),units="in", width=10, height=10, res=300);'\
'qq(asc$p, main = "Q-Q plot", col = "blue4");'\
'dev.off();'\
'noOfTests <- dim(asc)[1];bonf <- 0.05/as.numeric(noOfTests);bonfBy200 <- 10/as.numeric(noOfTests);'\
'sigSNPs <- asc$SNP[which(asc$p<=bonfBy200)];'\
'tiff(paste(args[2],".manh.tif",sep=""),units="in", width=30, height=10, res=300);'\
'manhattan(asc, main = "Manhattan Plot", chr = "Chr", bp = "bp", p = "p", snp = "SNP", ylim = c(0, 6),suggestiveline = -log10(bonfBy200), genomewideline = -log10(bonf), highlight = sigSNPs);'\
'dev.off();' "$input_asc" "$output_prefix"
Here is the Q-Q plot:
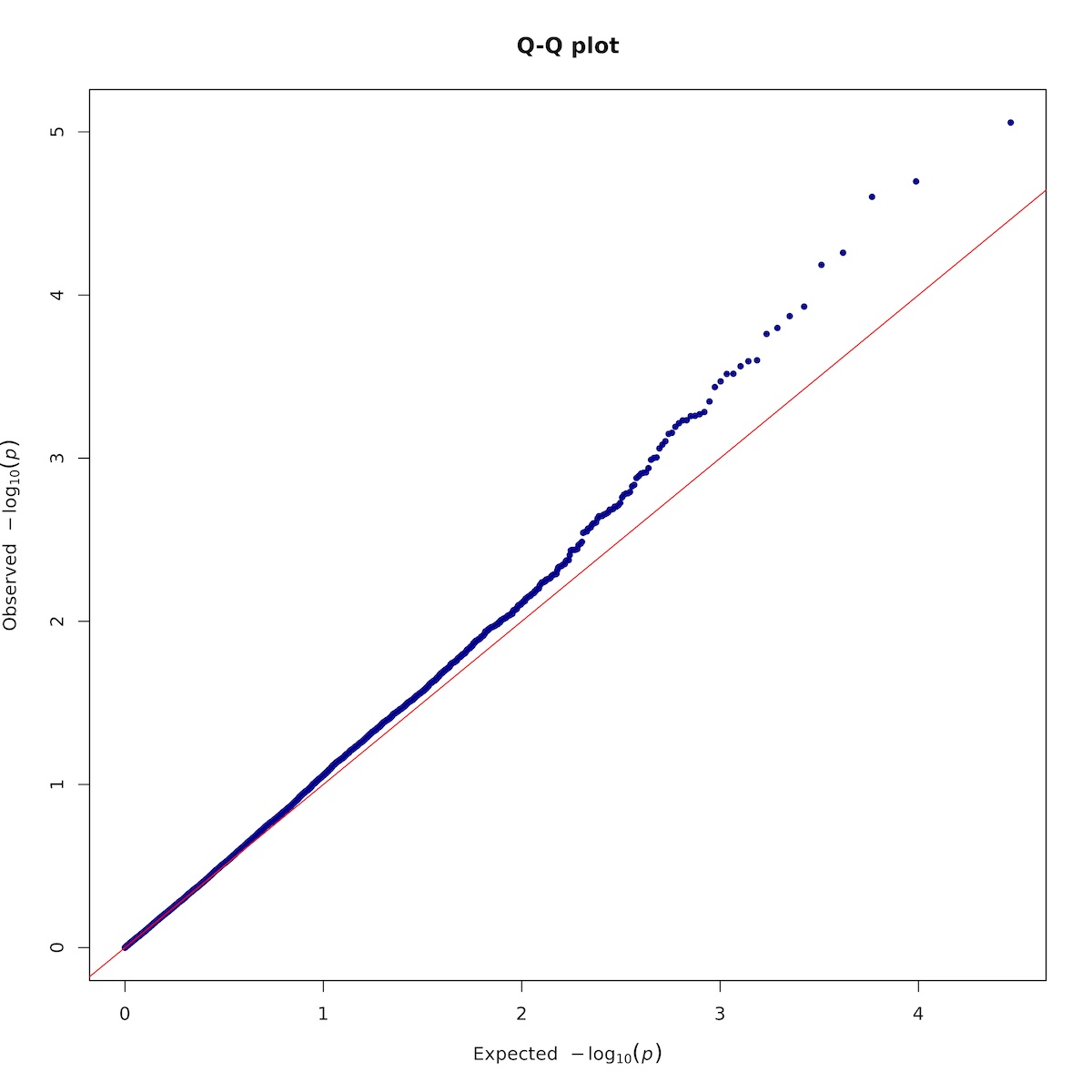
And the Manhattan plot